I've been working on an implementation of one of our proposals for
Scalable SMP Guest. I have a first pass at the patch and some numbers
to go along with it. In short, as of now, the over head of notification
is minimal at lower IO rates, more significant at higher rates. The SMP
performance under a lock-intensive load is not what we expected. Please
take a look at the patch, the test cases and the numbers. The patch was
generated against 20050502 nightly snapshot. Note that the patch
requires the presence of init/main.c in the sparse tree to apply.
------------------------------------------------------------------
Results:
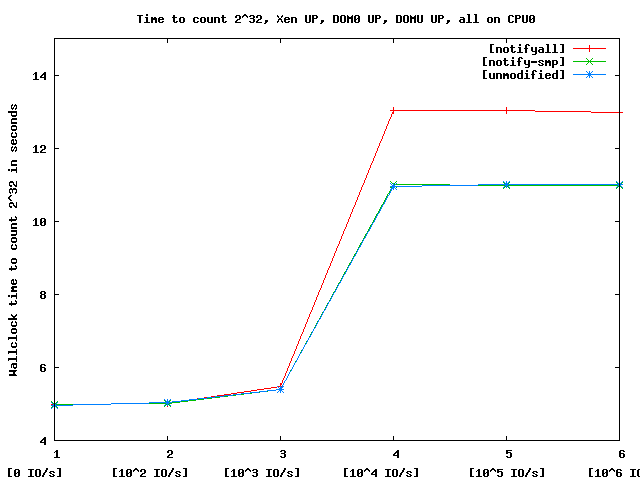
I've attached two png files to examine. The first file,
xenup_dom0up_domUup_varyio.png, shows three lines. The red line shows
the overhead of notification when both VCPUS in dom0 and domU running on
the same processor receive notification interrupts prior to preemption.
Any important optimization is to only send notification to SMP domains.
The green line shows that we incur no overhead when not sending
notification interrupts.
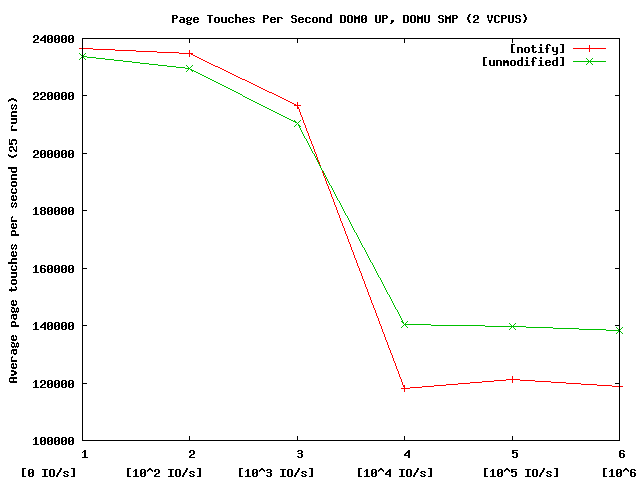
The second png file, dom0up_varyio_domUsmp.png shows how much the
notification helps/hinders in the case where IO issued to the dom0
processor is preempting one of the two vcpus in domU. The notification
should help prevent preempting a lock-holder resulting in more page
touches per second. We see that under 0 to 1000 IO/s there is a slight
benefit and as the IO rate increase, we hinder performance.
------------------------------------------------------------------
Questions:
First, we are puzzled by performance increase in the SMP case where the
IO load is zero. We expected that the overhead of the notification to
out weigh any benefit since the VCPU's context switch rate is at its
lowest.
Second, in both charts, there is a stair-step effect as we transition
between 1000 and 10000 IO/s. We have yet to determine the origin of
this effect. We are generating more data between these two points to
help determine the shape of that curve.
-------------------------------------------------------------
Setup used for testing:
Hardware
IBM PIII 866Mhz 2-Way, 896MB RAM
Xen Environment
Xen-unstable nightly snapshot 20050502
DOM0 512M RAM
DOMU 256M RAM , no swap
IO Generation
We utilized the ping utility on a private switch with a remote host
and the machine hosting dom0/domU. The ping command supports
setting a timer for the frequency of ICMP packets. We varied that
value from 0, to 0.000001 and sampled the performance of various
programs.
Testing UP Overhead with count
The overhead chart was generated with a simple c program which
counts from 0 to 2^32. We wrap the call to the program with
time and read the wallclock time.
Testing SMP perf with PFT
We run pft, with 128M split over two forks (64M a piece),
and pft runs 5 repeated runs.
http://k42.ozlabs.org/Wiki/PftPerformanceK42
pft is executed with the following wrapper
script:
#!/bin/bash
BIN="./pft"
MEM=$((${1}*1024*1024))
echo -n "#"
${BIN} -t -b${MEM} -r5 -f2
Sample output looks like:
# Gb Rep Thr CLine User System Wall flt/cpu/s fault/wsec
0 5 2 1 0.02s 0.45s 0.02s 139438.298 230997.254
Multiple runs are conducted since the results are inconsistent. To
average the results we take the 'fault/wsec' value for each 'Thr' line
in the output and produce an average over the total number of runs.
--
Ryan Harper
Software Engineer; Linux Technology Center
IBM Corp., Austin, Tx
(512) 838-9253 T/L: 678-9253
ryanh@xxxxxxxxxx
 preemption_notification.patch
preemption_notification.patch
Description: Text document
 xenup_dom0up_domUup_varyio.png
xenup_dom0up_domUup_varyio.png
Description: PNG image
dom0up_varyio_domUsmp.png
Description: PNG image
_______________________________________________
Xen-devel mailing list
Xen-devel@xxxxxxxxxxxxxxxxxxx
http://lists.xensource.com/xen-devel
|
{kind=link}
{kind=link}